XML Parsing
El XML (EXtensible Markup Language) es un metalenguaje de etiquetas extensible que se utiliza en muchas circunstancias, especialmente en aplicaciones que se comunican con otros servicios de Internet. El proceso de interpretación de los datos contenidos en un documento XML se denomina parsing.
En bada existe el namespace Osp::Xml, que permite la manipulación de documentos XML mediante la librería libXml2 (incluída en el SDK).
En este ejemplo aprenderás a parsear documentos XML con bada. A grandes rasgos, los pasos a seguir para hacerlo son los siguientes:1. Cargar el documento XML
2. Crear el contexto de evaluación XPath
3. Evaluar la expresión XPath
4. Obtener el contenido de los nodos deseados
5. Liberar recursos
NOTA: al final del post tienes la solución (proyecto bada) por si tienes problemas
El XML de muestra que utilizaremos es éste. Crea un documento con este contenido y guárdalo como "test.xml".
Se trata de un XML recibido en respuesta a una solicitud llamada GetNotes realizada a Facebook.
Crea un nuevo proyecto de tipo "Form based".
Guarda el fichero "test.xml" en la carpeta "/Home" del proyecto.
Para este ejemplo, necesitarás incluir los siguientes namespaces en "Form1.cpp"...:

...y las siguientes cabeceras en "Form1.h":

Antes de nada añade una List a IDF_FORM1 mediante el UI Builder, especificando el formato de elemento de lista ("List Item Format") como "LIST_ITEM_SINGLE_TEXT" y un ancho de columna ("Column 1 Width") un valor de 450, por ejemplo:

Ahora sigue estos pasos:
1. Primero se carga el documento XML.
Para ello, en el método OnInitializing() añade las siguientes líneas:

No olvides añadir la definición de la List en "Form1.h":

xmlReadFile() carga el documento XML y devuelve un puntero, doc, el cual organiza los datos en un árbol para facilitar el parseado de elementos individuales.
2. Luego se crea el contexto de evaluación XPath.
Añade estas líneas en el método OnInitializing():

XPath (XML Path Language) es un lenguaje que permite construir expresiones que recorren y procesan un documento XML. Una vez cargado el documento XML, la forma de seleccionar información dentro de él es mediante el uso de XPath. Con XPath puedes seleccionar y hacer referencia a texto, elementos, atributos y cualquier otra información contenida dentro de un fichero XML.
3. Ahora se evalúa la expresión regular en XPath para obtener el nodo "title".
Añade las siguientes líneas a continuación de las anteriores:

4. Ahora se recorren los nodos "title" contenidos en el XML y se añade su contenido (es decir, los títulos de los libros) a la lista.
Para hacerlo, añade las siguientes líneas acontinuación de las anteriores:
Luego, en el mismo "Form1.cpp", crea el método get_xpath_titles():

Y defínelo en "Form1.h":

Como puedes ver, el proceso de parsing es bastante sencillo con XPath. Si quisiéramos obtener otros datos, por ejemplo los autores, simplemente cambiaríamos la línea...:
xpathObj = xmlXPathEvalExpression((xmlChar*)"//title", xpathCtx);
... por esta otra:
xpathObj = xmlXPathEvalExpression((xmlChar*)"//author", xpathCtx);
5. Finalmente se liberan los recursos utilizados.
Añade las siguientes líneas en el método OnInitializing():

Ejecuta el proyecto. Deberías obtener algo como esto:
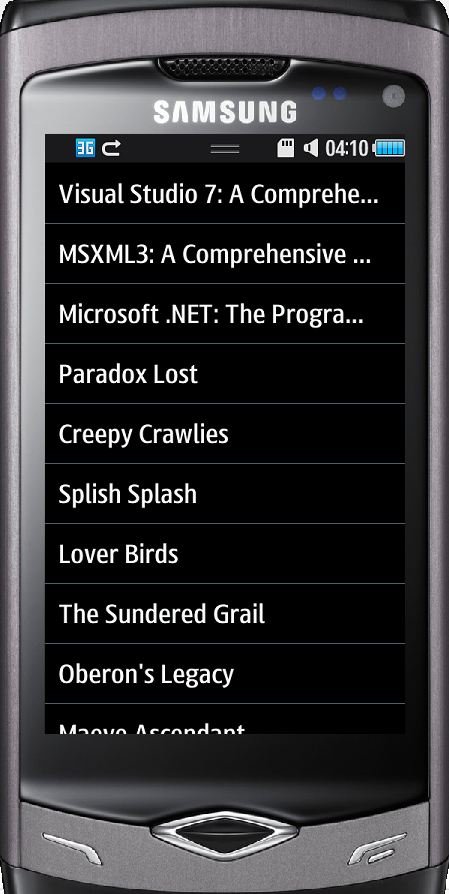
RSS Parsing
RSS son las siglas de Really Simple Syndication, un formato XML para sindicar o compartir contenido en la web. Se utiliza para difundir información actualizada frecuentemente a usuarios que se han suscrito a la fuente de contenidos. El formato permite distribuir contenidos sin necesidad de un navegador, utilizando un software diseñado para leer estos contenidos RSS (agregador).
Como RSS es simplemente un dialecto de XML, podemos aprovechar el código que hemos creado para el parsing XML, y simplemente sustituir el fichero "test.xml" de la carpeta "Home" por otro llamado "test.rss" (con este contenido).
Lógicamente, habrá que cambiar la línea ...:
doc = xmlReadFile("/Home/test.xml", NULL, 0);
... por:
doc = xmlReadFile("/Home/test.rss", NULL, 0);
La raíz de un fichero RSS es el tag "rss". Cada elemento de contenido es identificado por el tag "item", que es un nieto del tag "rss". Cada elemento "item" contiene el contenido que será transmitido a la web, y debería tener por lo menos un título ("title"), una descripción ("description") y un enlace al contenido completo ("link").
Supongamos que queremos cargar el título de cada item en la lista que creamos para el Xml Parser. Solo tendremos que sustituir la línea:
xpathObj = xmlXPathEvalExpression((xmlChar*)"//title", xpathCtx);
... por esta otra:
xpathObj = xmlXPathEvalExpression((xmlChar*)"//item//title", xpathCtx);
Cuando ejecutes el proyecto deberías ver esto en el emulador:


A continuación tienes la solución a los 2 ejercicios:
Vía: BadaDev





20 comentarios:
Muchisimas gracias por el aporte y la traducción al español.
Llevaba tiempo con el tema este del parsing XMl en Bada y no había forma de seguir el ejemplo del enlace que pusistes.
Por cierto, ¿Con el mismo código hay alguna manera de hacer algunas de estas dos cosas?
1- Mostrar titulo y a continuacion del libro el autor
2- Leer el nodo book y mostrar su atributo id o atributos en caso de haber varios
Muchisimas gracias de nuevo por el aporte
Hola Bernon,
Una manera de obtener varios atributos (por ejemplo el autor y el titulo) es mediante un OR (|), es decir cambiando la línea:
xpathObj = xmlXPathEvalExpression((xmlChar*)"//title", xpathCtx);
Por esta:
xpathObj = xmlXPathEvalExpression((xmlChar*)"//author|//title", xpathCtx);
Como en un comentario no puedo explicar todo XPath y no es el tema de este post, dejo un enlace a un tutorial de XPath en español y un enlace a la nueva solución (proyecto badaIDE)
Tutorial:
http://geneura.ugr.es/~victor/cursillos/xml/XPath/
Proyecto bada IDE con la solución:
http://www.megaupload.com/?d=4WXGGC7G
Por cierto, muchas gracias a todos vosotros por seguir el blog !!
A ti por el trabajo y el seguimento realizado al nuevo SO móvil de Bada
hola Byron, probe el ejemplo que enviaste y no funciona trate de corregirlo pero al hacerlo me sale un error que dice que no encuentra el nombre del proyecto.exe (XMLtest.exe not found) si me pudieras dar una ayuda, si quieres te dejo el codigo fuente aca: http://www.megaupload.com/?d=3LGWB9Y1 por si lo quieres ver.
Gracias.
Hola Byron, necesito cargar imagenes desde internet tienes idea como se puede hacer?
¿Qué tal?
Te paso un ejemplo que muestra cómo cargar imágenes desde una URL:
http://en.androidwiki.com/wiki/Loading_images_from_a_remote_server
Supongo que te refieres a eso.
Hola Bayron gracias por tu ayuda, pero mi duda es en Bada ya que no encuentro documentacion o un ejemplo de esto? Gracias.
Sí, perdona, me confundí con Android.
Pues te puedes mirar este ejemplo:
http://forums.badadev.com/viewtopic.php?f=6&t=1161&start=0
Básicamente la imagen remota se carga con:
pImageDownloader->DecodeUrl(*uri, BITMAP_PIXEL_FORMAT_RGB565, 480, 600, MAP_IMAGE, *this, timeout);
Y luego se representa en el método OnImageDecodeUrlReceived()
¡Espero que te sirva!
a lo mejor es un poco tarde preguntar xD pero también sirve para rss?
Nunca es tarde ;)
Te dejo un par de enlaces que te pueden servir:
http://static.bada.com/contents/docs/apis/bada-V1.0.0a3/framework/classOsp_1_1Content_1_1RssManager.html
http://lovedale.wordpress.com/2010/12/07/parsing-rss-feeds-in-bada/
¡Suerte!
mercii!!!y felicidades por le foro!!, ahora mismo me pondré con el rss que me interesa muchísimo!
siento molestar pero he intentado hacerlo y no funciona, :S, podrías hacer un tuto del rss? te explicas super bien y te entiendo mucho mejor que el inglés xD o si me dices donde hay un ejemplo también te lo agradezco xD
Es muy sencillo, puedes aprovechar el código del xml parser que comento en este post.
De todas maneras, he visto que el enlace a la solución del XML parser estaba mal y he actualizado el post.
Míralo, igual te llevas una sorpresa ;)
me he equivocado en el coment xD, bueno al final me he bajado la solución para ver como está hecho, y dice algo de que no encuentra el archivo 2.0.0 (ni idea) igualmente el mio si que funciona (mas o menos xD)le faltaba un; a un Osp::etc etc,
Publicar un comentario